
데이터 라벨링이란 무엇일까요?
우리가 흔히 아는 인공지능(AI)의 고도화를 위해서는 다양한 데이터를 주입해야합니다.
AI는 사람이 사용하는 문서나 사진 등의 데이터를 식별할 수 없기 때문에
AI가 스스로 학습할 수 있는 형태로 데이터를 가공해야하는데,
이러한 작업을 데이터 라벨링이라고 합니다.
즉, 데이터 라벨링을 하는 사람을 데이터 라벨러라고 부릅니다.
데이터 라벨링의 예를 들어보자면.

강아지 사진과 동영상 등에 데이터 라벨러가 '강아지'라는 라벨을 붙이면,
AI는 이러한 데이터들을 학습하면서 유사한 이미지, 동영상을 강아지라고 인식하게 됩니다.
보라색 네모칸을 바운딩이라 합니다.
바운딩 안에 들어간 대상을 '강아지'로 인식시켜 수만은 데이터로 꾸준히 학습을 시켜줍니다.
우리가 당연히 알고 있는 강아지, 컵, 컴퓨터, 책상 등
인공지능은 단지 숫자로만 보기 때문에 대상이 무엇인지 알지 못합니다.
그렇기 때문에 인공지능을 개발하기 위해서는 각각이 무엇을 의미하는지
표시해 학습을 시켜야 합니다.
이건 강아지이다.
이건 고양이이다.
이건 책상이다.
하나씩 표시해서 인공지능을 학습스켜야 하는걸
데이터 라벨링이라고 합니다.
이를 작업하는 사람을 데이터 라벨러라고 부릅니다.
이해가 되셨나요?
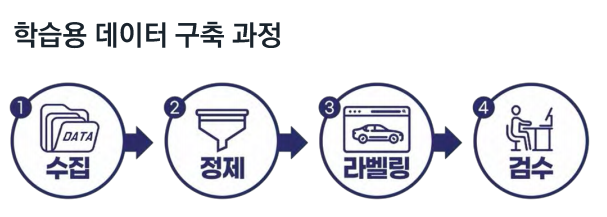
데이터 라벨링을 하기 위해서는 총 네단계로 구분됩니다.
1. 데이터의 '수집'
2. 인공지능이 학습할 수 있는 형태로 바꿔주는 '정제' 과정
3. 학습하고자 하는 데이터를 찾아 라벨을 달라주는 '라벨링' 작업
4. 잘못된 학습 결과를 잡아주는 '검수' 작업
이 글을 읽고 계신분들은 대게 데이터 라벨러를 생각하고 계실겁니다.
데이터 라벨링에 관해 앞으로 꾸준히 포스팅할 예정으로 함께 좋은 결과를 만들었으면 합니다.
과기부-NIA, AI용 데이터 기술 고도화-인재양성 팔걷었다
과기부-NIA, AI용 데이터 기술 고도화-인재양성 팔걷었다
전 산업 분야에서 인공지능(AI) 활용이 급증하고 시장도 빠르게 성장하면서 AI용 데이터의 중요성은 갈수록 커지고 있다. 이에 맞춰 AI용 데이터의 품질 향상, 관련 기술의 고도…
www.donga.com
전 산업 분야에서 인공지능(AI) 활용이 급증하고 시장도 빠르게 성장하면서 AI용 데이터의 중요성은 갈수록 커지고 있다. 이에 맞춰 AI용 데이터의 품질 향상, 관련 기술의 고도화 및 인재 양성에 초점이 맞춰진 지원 사업도 다양해지고 있다.
과학기술정보통신부(장관 이종호)와 한국지능정보사회진흥원(NIA·원장 황종성)은 AI 연구와 새로운 서비스 개발에 필요한 대규모 학습용 데이터를 AI 허브에 축적해 각 분야에 지원하고 있다. 이와 함께 올해 ‘2022 한국어 AI 경진대회’ 및 ‘2022 AI 데이터 품질개선 오픈 랩’ 등을 추진하며 다양한 혜택을 제공하는 등 인재 발굴 및 기술 제고를 위한 노력을 기울이고 있다.
7월부터 10월까지 진행된 ‘2022 한국어 AI 경진대회’는 AI의 한국어 음성인식 성능 제고를 위해 마련됐다. AI 허브에 추가로 개방된 한국어 AI 학습용 데이터가 활용된 이 대회에는 전국에서 대학생, 기업 등 총 226개 팀이 참가했다. 현대자동차와 네이버클로바는 대회 기획부터 함께 참여했다. 대회 입상자들에게는 이들 기업 입사 서류전형 때 가산점이 주어진다. NIA는 앞으로도 이 대회를 이어가 관련 기술의 고도화, 인재 발굴 및 양성을 계속할 방침이다.
‘2022 AI 데이터 품질개선 오픈 랩’은 올해 처음 시작한 논문 지원 프로그램이다. 현업에서 활동하고 있는 이들이 현장에서 느끼는 학습용 데이터의 품질 문제와 그 해결 방안을 위한 연구를 촉진하기 위해 마련됐다. 8월 중순까지 연구계획서 신청을 받아 선정된 대상자들이 11월까지 논문을 작성하도록 했다. 이 중 3편의 논문이 한국정보과학회 학술지에 실릴 것으로 기대된다. 관련 내용은 AI 학습용 데이터 구축사업의 품질관리 가이드라인에 반영될 예정이다.
AI 데이터 산업계 내에 필요한 크라우드워커(데이터 라벨러 등)를 육성하기 위한 전문 교육도 확산하고 있다. AI의 필요에 맞게 데이터를 가공하는 데이터 라벨링은 나이 성별에 관계없이 누구나 할 수 있지만 이 데이터의 품질은 AI의 성능에 큰 영향을 끼친다. 정부와 NIA는 5대 권역별 현장 및 온라인 강의를 통해 AI 학습용 데이터 라벨링 전문교육을 실시했다. AI 윤리 및 관련법부터 이미지 영상 텍스트 등 데이터 유형별 라벨링 및 전문가 과정 등이 운영되고 있다. 현재까지 1만여 명이 교육과정을 수료했다.
또 올해 AI 학습데이터 직무를 국가직무능력표준(NCS)에 등록함에 따라 데이터 라벨링 등의 직무를 교육하거나 관련 인원을 채용할 때 표준화된 내용을 적용할 수 있도록 했다. 데이터 라벨러가 하나의 정식적인 직업으로 공인됐음을 의미한다.
아울러 고려대 연세대 성균관대 등 대학 내 AI 데이터 관련 수업에 참여한 학생들에게 AI 허브 데이터를 제공해 AI 모델을 손쉽게 실습할 수 있도록 했다. 올해에는 1학기 3개 대학, 2학기 8개 대학의 총 18개 강의에 600여 명의 학생이 참여했다. 대학들과의 협업은 내년에도 지속될 예정이다.
NIA 관계자는 “AI 데이터 생태계의 활성화 및 선순환 기반 구조를 구축하고 혁신적 가치를 창출하기 위해 인재 양성 및 관련 지원을 계속할 방침”이라고 했다.
이원홍 기자 bluesky@donga.com
'데이터 라벨링' 카테고리의 다른 글
| 크라우드웍스 AIDE 2급 취득 후기 (1) | 2022.12.24 |
|---|---|
| 빅데이터·인공지능·클라우드 통해 진화 중인 ‘검색엔진’ (0) | 2022.12.24 |
| 영수증 앱테크 : 칸타모바일패널 가입했습니다. (0) | 2022.12.23 |
| '데이터 라벨러' 새 직업으로 공인(NEWS) (0) | 2022.12.21 |
| 크라우드웍스, 코스닥 상장예비심 청구 (0) | 2022.12.21 |



